为超过 100 万开发者提供专业的 API 服务,所有 API 均提供免费的服务


引言
在过去的几十年里,文本纠错技术已经取得了巨大的进展,从最初的基于规则的纠错系统到现在的基于机器学习的纠错系统,技术的发展已经帮助人们解决了大量的文本纠错问题,随着机器学习技术的发展,文本纠错技术也发生了重大变化。
本文将介绍一款新的基于机器学习的纠错技术,并详细列出实际的可应用场景。
工作原理
今天介绍的智能文本纠错 API 是基于机器学习的纠错系统通过分析大量的文本数据来学习语言模型,从而识别和纠正文本中的错误。这种方法不仅能识别语法和拼写错误,还能识别语境相关的错误,例如使用不当的词语。
基于机器学习的文本纠错系统通常分为两个主要部分:语言模型和纠错算法。
语言模型是根据大量文本数据训练得到的,可以预测一个词语在语言中的概率;纠错算法则根据语言模型的预测结果和词语的上下文信息来识别错误并纠正它们。
纠错能力
智能文本纠错技术是针对字词错误、标点、地名、专有名词、敏感信息、意识形态等进行智能校对,具体的纠错能力如下:

应用场景
当前的基于机器学习的智能文本纠错 API 已经非常成熟,并且广泛应用于各种领域,例如写作工具、手机输入法和翻译软件等,下面是一些常见的应用场景:

快速接入智能文本纠错 API
1.注册并获取智能文本纠错 API 密钥
进入 【智能文本纠错】详情页,点击【免费试用】,即可唤起注册按钮。
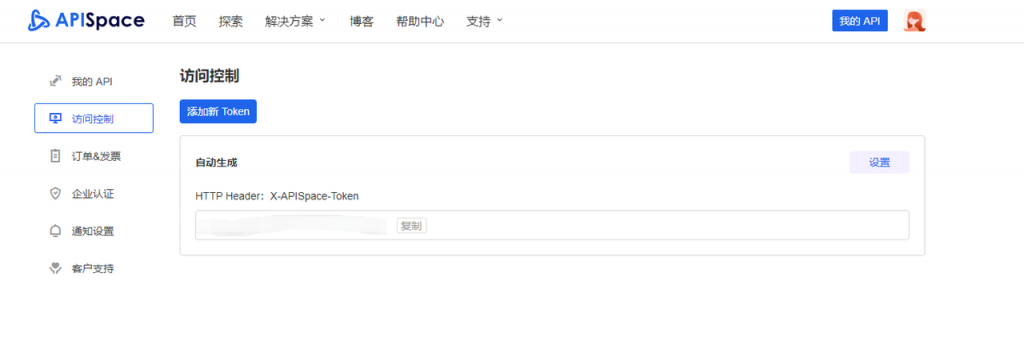
注册成功后,我们在页面导航菜单点击【我的 API】进入【访问控制】页面,即可看到平台提供的密钥。
2.调用API 接口
构建API 请求
var data = "{\"text\":\"传承和弘扬中华优秀传统文化既是增强文华自信、建设社会主义文化强国的应然之义,也是全面建设社会注意现代化国家、推进实现中华民族伟大复兴的实践前提。\"}"
$.ajax({
"url":"https://23331.o.apispace.com/text-detection/check",
"method": "POST",
"headers": {
"X-APISpace-Token":"替换成平台提供的API 密钥",
"Authorization-Type":"apikey",
"Content-Type":"application/json"
},
"data": data,
"crossDomain": true
})
.done(function(response){})
.fail(function(jqXHR){})
3.返回数据内容
{
"sum": 2,
"msg": "",
"result": [{
"sentence": "传承和弘扬中华优秀传统文化既是增强文华自信、建设社会主义文化强国的应然之义,也是全面建设社会注意现代化国家、推进实现中华民族伟大复兴的实践前提。",
"position": 0,
"shareDicId": null,
"mistakes": [
[
[17, 19], // 错误在句中的位置,左闭右开
[
["文化", 2, "1-1", 0] // [推荐词,推荐程度,推荐类别,命名实体标志]
],
[]
],
[
[46, 48],
[
["主义", 2, "1-1", 0],
["主易", 2, "1-1", 0],
["主意", 1, "1-1", 0]
],
[]
]
],
"mistakeNum": 0
}]
}返回参数中 mistakes 字段详解
0: 错误在句中的位置[l, r),左闭右开
1: 推荐意⻅(list)
0: string 推荐词
1: int 推荐程度
1: 表⽰“低概率错误,⼀般推荐”
2: 表⽰“⾼概率错误,强烈推荐”
3: 系统默认敏感词
4: ⽤⼾⾃定义敏感词
5: ⽤⼾⾃定义错词
6: 共享词典敏感词
7: 共享词典错
8: 标点符号错误
2: 推荐类别, 格式”x-x”
“0-x”: 默认分类 (没有对应分类)
“1-“: 表⽰同⾳错误,建议替换
“2-“: 常⻅谐⾳错误,建议替换
“3-“: 遗漏字词错误,建议补充
“4-“: 冗余字词错误,建议删减
“5-“: 其他谐⾳、近形错误,建议替换
“7-“: 语序错误,建议调整语序
“8-x”: 敏感词错误,建议删减
8-1: 未分类(默认分类)
8-2: ⻩赌毒
8-3: 司法、政治
8-4: 宗教、迷信
8-5: ⾔语 辱骂
8-6: ⾮法信息
8-7: 宣传、⼴告
“9-1”: 地址归属地错误
“10-x”:
10-1: 中英类型错⽤
10-2: 成对标点缺失或⽤反
10-3: 多余标点
3: 0/1 命名实体标志。0: ⽆命名实体;1: 有命名实体。
2: 空结语
在这篇文章中,我们探讨了智能文本纠错 API 的应用场景,智能文本纠错技术在很场景都得到了广泛实施,帮助人们解决了大量的文本纠错问题,而智能文本纠错 API 的出现,则为开发者提供了一个更加便捷的方式来获取智能文本纠错技术,从而可以为用户提供更好的服务和体验,带来的商业价值也日益凸显,有需要赶紧用起来吧~
Last Updated on 2023-04-28 by admin






